php中for循环的极致性能论证
简介:
测试环境:
PS F:\Study-work\php\ceshizhuanyong> php -v
PHP 7.2.4 (cli) (built: Mar 28 2018 04:27:01) ( ZTS MSVC15 (Visual C++ 2017) x64 )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
说法一:【for($i = 0; $i < 10000; $i++)】中$i++如果改成++$i速度将会提升
测试:
代码如下:
<?php
//php官方手册封装的一个用于获取当前含微秒时间的函数,所以我怎么可能客气呢
function microtime_float()
{
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
$arr = []; //预定义数组,方便统计平均数
for($j = 1; $j <=10; $j++){ //避免出现误差,直接连续测十次
$start_time = microtime_float(); //获取初始时间
for($i = 0; $i < 10000; $i++){ //测试一万次循环下$i++和++$i的用时
continue; //直接跳过,避免影响对结果的判断
}
$end_time = microtime_float(); //获取结束时间
$arr[$j] = ($end_time-$start_time); //保存至数组,后面计算
echo "第{$j}次用时:".($end_time-$start_time)."秒\n"; //输出每一次的结果
}
echo "平均用时:".(array_sum($arr)/10)."秒"; //计算平均值
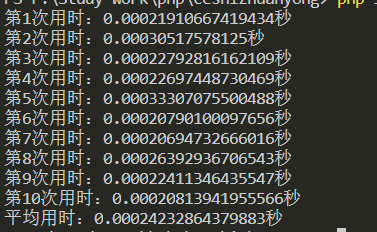
$i++结果如下:
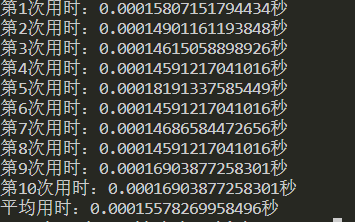
++$i结果如下:
所以,结果是:
一万次循环下$i++比++$i快了0.00009秒
四舍五入那可是一个亿呢0.0001秒呢!时间如金呀!

不过这是量级不够的情况下,如果我们将次数再翻一万倍,提高到1亿次,前后写++影响可以达到一秒左右。
原理:
$i++是先引用,再对$i进行自增,而++$i是先对$i进行自增,然后再进行引用。
如果是一个完整的函数的话,那么$i++需要做的就是以下三步
$j = $i;
$i += 1;
return $j
++$i需要做的是
$i += 1
return $i所以,$i++在执行的时候,将会在内存中多开辟一个临时变量的位置,那么,效率肯定要低。
所以结论是:
一般数据量下,两种写法的差距影响并没有那么大,所以,怎么写都行,如果在亿级数据量时,++$i的写法可以影响该循环提高程序运行时间一秒左右的时间。
说法二:遍历数组时【for($i = 0; $i < count($arr); $i++)】速度很慢
测试:
普通写法代码如下:
<?php
//php官方手册封装的一个用于获取当前含微秒时间的函数,所以我怎么可能客气呢
function microtime_float()
{
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
$list_arr = []; //生成一个用于遍历的数组
for($i=0;$i<10000;$i++){ //数组长度为一万的
$list_arr[$i] = $i;
}
$arr = []; //预定义数组,方便统计平均数
for($j = 1; $j <=10; $j++){ //避免出现误差,直接连续测十次
$start_time = microtime_float(); //获取初始时间
for($i = 0; $i < count($list_arr); ++$i){ //普通的写法,后面果断使用++$i提高运行速度
continue; //直接跳过,避免影响对结果的判断
}
$end_time = microtime_float(); //获取结束时间
$arr[$j] = ($end_time-$start_time); //保存至数组,后面计算
echo "第{$j}次用时:".($end_time-$start_time)."秒\n"; //输出每一次的结果
}
echo "平均用时:".(array_sum($arr)/10)."秒"; //计算输出平均值
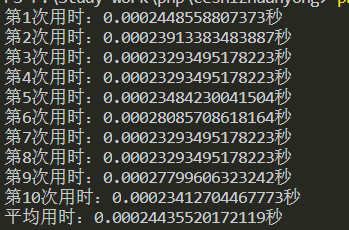
结果如下:
将for换个写法,代码如下:
<?php
function microtime_float()
{
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
$list_arr = [];
for($i=0;$i<10000;$i++){
$list_arr[$i] = $i;
}
$arr = [];
for($j = 1; $j <=10; $j++){
$start_time = microtime_float();
//将count位置换到第一段代码定义,并在后面仅选择变量
for($i = 0, $count = count($list_arr); $i < $count; ++$i){
continue;
}
$end_time = microtime_float();
$arr[$j] = ($end_time-$start_time);
echo "第{$j}次用时:".($end_time-$start_time)."秒\n";
}
echo "平均用时:".(array_sum($arr)/10)."秒";结果如下:
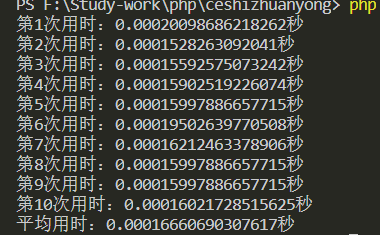
所以结果是一万次循环平均快了0.00008秒
结果与上面$i++的写法的影响近乎一样
同理,亿级数据一样影响接近一秒的时间差值。
原理:
这个是因为for循环执行顺序的问题,for循环执行顺序如下:
for(第一段;第二段;第四段){
第三段
}
第一段仅在循环开始之前执行,整个循环仅执行一次;
然后每次循环过程依次执行判断第二段布尔值,执行第三段,第四段代码;
所以因为第二段代码每次循环都要执行,$i<count($arr)的写法将会将count这个函数执行N次;
如果将函数放到第一段里进行定义或者循环外部定义,那么速度肯定会更快。
所以结论是:
和上面差不多。一般情况下,影响不大,亿级数据将会影响明显;
所以以后我的for循环遍历就这么写了:
for($i = 0, $c = count($list_arr); $i < $c; ++$i){
continue;
}
最后试试,php7.2.4版本下两种方法都用和不用的万次循环差别:
for($i=0;$i<count($arr);$i++){}的结果如下:

for($i=0,$count = count($arr);$i<$count;++$i){}的结果如下:
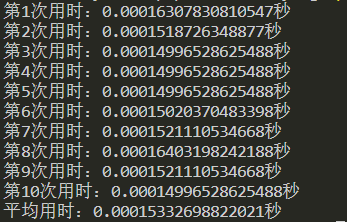
时间差值约为:0.00013秒
其实是接近一倍的时间存在
php5.6.34版本下两种方法都用和不用的万次循环差别:
for($i=0;$i<count($arr);$i++){}的结果如下:
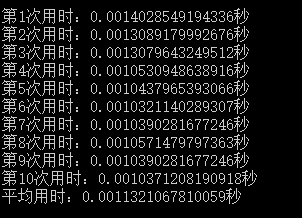
for($i=0,$count = count($arr);$i<$count;++$i){}的结果如下:
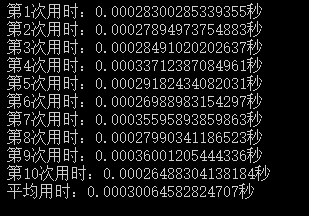
时间差值约为:0.0008秒
差值已经非常明显,亿级数据可以直接差别到8秒钟










在下看个结论就够了,,,评论加个表情包吧☺,再加个回到顶部的按钮吧,,,,▲